KEY TAKEAWAYS
- K2view is a user-friendly tool that works on a large scale.
- Privitar ensures anonymization while keeping the analytical value.
- Tonic.ai is best for developers.
- DataVeil is a robust, secure, and simple solution.
We are living in an era where data anonymization is no longer an afterthought or something that can be ignored. Today, it’s a necessity. If you’re building customer-facing applications, conducting research for new products, or just archiving sensitive data sets, how you anonymize data determines whether trust is built.
Let’s be honest, data breaches and AI scraper tools have become a major issue, and traditional methods are no longer effective in stopping them. If you wish to stay compliant but still be innovative without any restraints, below are the top 7 data anonymization tools to consider in 2025.
K2view has become an enterprise favorite in areas where speed and large-scale anonymization are a must. This isn’t a clunky, hard-to-integrate tool—it’s a nimble, efficient, and user-friendly solution.
Its real strength, though, lies where both structured and unstructured data can be handled without losing referential integrity. That way, apportioned customer data across multiple databases can be anonymized but still kept as logically as possible.
What K2view does especially well in 2025 is its PII discovery and synthetic data generation options. If your QA teams need precise datasets, just as production, K2view can produce them in conformance with global frameworks like GDPR and HIPAA.
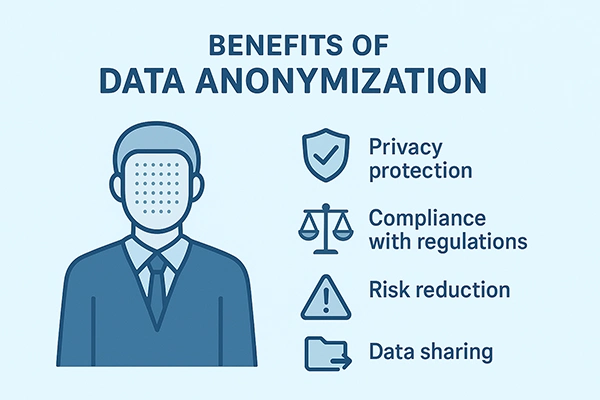
It offers 200+ out-of-the-box data masking methods, role-based access control, referential integrity, and semantic security across source systems, and more! Below, you can see the major benefits of data anonymization.
Privitar has evolved significantly over the past few years, from being a compliance tool to a complete data privacy platform. The building blocks of Privitar are strong policy regulations. It doesn’t just sanitize data, but restructures data with context-aware techniques, having a fine balance between high utility and minimal risk.
The reason it’s popular in 2025 is that it coincides with responsible AI use. As companies feed more data into machine learning pipelines, Privitar ensures anonymization doesn’t strip datasets of their analytical value.
Tonic.ai is a developer’s best friend. Unlike a set of platforms developed with compliance officers, it caters to engineers. It’s all about giving your devs and QAs access to de-identified, securely stored datasets that function precisely like real production data.
Tonic differs by mathematically simulating synthetic data that is similar to your real data. This comes especially useful with fintechs, e-commerce platforms, and health tech companies, where action patterns that look real are crucial during tests.
And it integrates perfectly with CI/CD pipelines, so anonymization comes as an integral part of your regular software life cycle, not a post-mortem task.
Not every organization needs a data privacy suite that’s all-singing, all-dancing. Sometimes, a robust, secure, and simple appliance just does the trick. That’s where DataVeil comes into its own.
DataVeil doesn’t overwhelm with a raft of options—it gives you just what you need to get the job done: de-identification, masking, and tokenization, with data format and structure remaining unchanged.
DataVeil is suitable for small IT departments that need to anonymize databases quickly with a small learning curve. It handles large-scale rewrites well, and its interface is easy to use and polished.
Statice operates in that sweet spot, which is between academic-grade anonymization and real-world usability. It emphasizes privacy by preserving data transformation that don’t compromise statistical power. This makes it a reasonable choice among data science teams that have to anonymize data but can’t handle having to compromise predictive accuracy.
Its privacy engine includes support for differential privacy and higher-level k-anonymity methods, so you are not randomly shuffling columns—you’re applying established statistical models to mitigate re-identification risk.
Anonos has taken a step further from other data anonymizers by building what it calls a “Data Embassy.” It’s an end-to-end encryption solution for the age of AI, where data needs to be transferred across borders, partners, and applications—safely.
It doesn’t anonymize existing data, but creates encrypted data derivatives that retain both legal and intellectual value. This becomes even more serious as more and more businesses train broad language models or pipe data into external analytic applications.
With Anonos, you’re not de-identifying PII—you’re enabling legal, controlled data flow with no loss of privacy or agreement violations.
IBM Data Privacy Passports may not be a new name, but they continue to improve well into 2025. It’s a data-centered security idea—you don’t disclose data once to one use case; you control where it’s extracted and decrypted, where it travels.
It’s incredibly helpful with hybrid and multi-cloud environments. Furthermore, it uses encryption and dynamic data masking to grant different levels of view to data according to a user’s geographic position or their role.
As we move deeper into the AI era, data complexity and data volume are exploding. Complacency-driven suggestions simply don’t hold up any further. You’re going to need solutions that balance aesthetics, privacy, and performance—that understand how to neither merely hide data, but sustain its usability throughout use cases.
These seven tools are something more than GDPR checkboxes—they’re innovation accelerators. If you’re trying new apps, training models for AI, or transacting across borders, having the right anonymization layer is the difference between effective growth and risky unauthorized access.
Data anonymization alters the data so that it can’t be identified directly, indirectly, or with the rest of the data in hand. It masks it completely and makes it safer to share.
Data anonymization is a considerably less expensive solution for storing data, collecting it, or processing it in comparison to raw data.
Anonymized data can be identified with de-anonymization. This can include linkage attacks, which are known to involve cross-referencing anonymized data with public records, and inference attacks.