As businesses progress further into an era of competition that’s driven by data, it’s become more vital than ever before to be able to collect, process, and pull insight from it at scale. Around 97% of all businesses across the globe currently engage with big records, with the vast majority actively investing in its architecture, management strategies, and teams.
Yet, companies that want to manage information are faced with a growing problem: its expansion at rapid levels. 90% of all of the data ever created came into the world over the last two years, with institutions having to contend with more sources of information and changing formats of it. To effectively rise to this challenge, we must invest in data architecture and construct a stable structure that can manage this scaled demand.
In this article, we’ll dive into everything your company needs to know about data architecture, comment on what infrastructure includes, why we need it, and share tips for success.
Let’s dive right in.
Data infrastructure is an umbrella term that refers to all the foundational aspects that underpin an effective collection strategy. Beyond just the architecture that sustains the pipeline, the structure also includes analytical tools and systems that a company uses to draw insight from its input.
Typically, it includes the following areas:
With all these moving parts, it’s no surprise that companies are sometimes unsure of where to begin while creating data infrastructure.
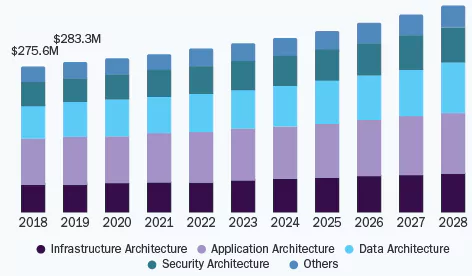
(This graph shows the U.S. Enterprise architecture market size, by solution, from 2018 to 2028, in US$ Billion).
When a business sets a goal of expanding its data infrastructure, it normally does so in light of a specific target or goal that they have introduced. For example, does it want to spend less on storage, improve customer experiences, or maybe do several things? Understanding why you want to improve the existing one should always be the first point of departure.
Outlining the goals of the input modernization will allow the firm to arrive at its targets more effectively. Equally, the specific goals you have will shape the tools and systems that are to be employed. Beyond the core components that we outlined above, there are numerous additions that a company can make to expedite its progress toward a goal.
After outlining the core goals, we suggest that you follow these steps and strategies:
Looking for technologies that will support security, storage, networking, and more may seem overwhelming. In light of the sheer number of choices an organization has, many simplify their choices by picking one provider that manages everything. While this is certainly a simpler approach, it could lead to vendor lock-in, which may perturb the business in the future.
Instead of choosing a singular technology or provider for all services, carefully consider which partner you want to choose for each part of the data architecture. Consider scalability, capacity, performance, cost, and any other factor that’s significant to the company.
These initial planning choices are not an exciting phase of information modernization but are vital for the future.
A common mistake that businesses make when constructing their base of data infrastructure is to launch into operation without properly considering compliance and governance. By law, companies must follow a strict set of regulatory standards when dealing with records, especially any information that is garnered about or from customers.
Before launching into operation, ensure that the organization understands the requirements that must be followed. Across the board, you should prepare for security, quality assessment, and compliance. Establish these processes as early as possible to avoid any major issues down the line.
After you have established them, members of the team can be assigned to become the head of compliance. This level of responsibility will ensure accountability when constructing the info pipeline and help compliance appear everywhere it should be.
A key aspect that the business should take into account when constructing data architecture is, where possible, to look for areas that can be automated. In the pipeline, human error is consistently the mistake that causes the most problems. Automation completely eradicates this possibility while also speeding up the flow of information throughout the dealings.
The company can automate fundamentally any area of the pipeline, from compliance to input collection, allowing it to rapidly improve the base structure and prepare for a scalable future. As businesses continue to process more and more records, the ability to scale through automation is a useful priority that should be assigned when constructing data architecture.
Constructing a comprehensive expanse of data architecture is a challenging task. Considering the speed with which the industry continuously invents and reinvents itself, there are always new platforms, systems, and tools that a business can integrate to enhance its infrastructure.
A fantastic example of this is the fairly recent expansion of AI services, which has helped to streamline several areas of the pipeline and expedite automation.
That said, there are certain fundamental building blocks that every company must be able to employ to construct a successful system. Taking board the tips in this article and focusing on the core areas outlined will point the organization toward a more effective method of building and sustaining data architecture.
Once you have laid the foundations, the perfect base is ready to begin expansion in any direction the business sees fit.