The process of finding the most efficient execution plan to improve the performance of the database queries is known as query optimization.
Poorly written or designed JOINs, and using them without indexes, can degrade the function of the database.
Minimize the use of SELECT*, ORDER BY, and GROUP BY in the query, as it can negatively impact the way the database runs or functions.
Make use of the Caching Mechanism to reduce the cost database.
Regularly update your database statistics and indexes to ensure accurate query optimization.
Let’s say, for instance, that you are doing a project that relies on a really massive database.
Everything is working out just fine until your queries start taking more time than they usually should.
You try making some optimizations, but there is absolutely no change in performance, and it is now risking the entirety of your project.
Does this scenario ring any bells for you?
If yes, then now is a good time to start learning about SQL (Structured Query Language).
It is a program that is already executed by 72% of developers on a day-to-day basis to manage large or complicated databases (Source: nucamp, 2025).
To help you know more about this subject, this blog has given some pointers to optimize your queries so that you can work more productively.
Continue reading to find out how!
Understanding Query Optimization
The database has several ways to retrieve the data, and when searching for this report or detail, it’s known as a query.
Query optimization is a way of selection that enables the directory to use the fastest technique available to recover the needed information.
This ensures that the record spends minimum resources, such as time or processing power, when answering the user’s doubt, and as a result, it’s more efficient.
Following, developers and database administrators are often advised to use a SQL cheat sheet to get quick access to necessary commands, and best practices.
A well-structured directory schema and indexing strategy play an integral role in ensuring that queries run efficiently and data retrieval processes remain swift.
Core Functions of a Query Optimizer
To ensure an efficient database retrieval, the query optimizer manages a suite of core operations, including the analysis of statements, evaluating plans, and so on.
1. Use Indexing for Faster Lookups
Inside a big library with countless books lining the walls, it can be challenging to find a specific book.
But using the index in the back, the task can become easier, and you can find what you have been looking for faster.
That’s how it works in a database; it allows the system to speedily locate specific data and access the rows within a large table.
2. Avoid SELECT
Be sure that you have not been using SELECT * as it can have a negative impact on the performance.
It retrieves all columns from a table, including those not needed for your specific operation, which can be inefficient, especially in large databases.
3. Optimize Joins and Use the Right Type
When joins are written poorly, it can slow down the performance of queries, mainly when dealing with large databases or complex statements.
Therefore, it is advisable to use appropriate join types such as INNER JOIN, LEFT JOIN, and RIGHT JOIN.
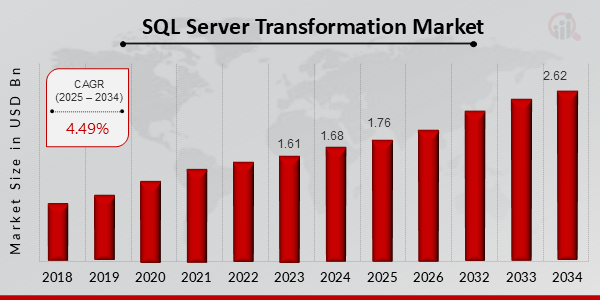
The graph below shows that the SQL Server Transformation Market is projected to grow from USD 1.76 billion in 2025 to USD 2.62 billion by 2034.
4. Utilize Query Execution Plans
Provided by the database management system, the query execution plan acts as a roadmap that outlines the SQL tutorial for how the statements will be executed.
Having a look at your EXPLAIN (MySQL, PostgreSQL) or SHOWPLAN (SQL Server) results can reveal a way you can optimize the query for improved performance.
5. Implement Proper Data Partitioning
It is a process of dividing a partitioned table into smaller subsections or fragments, which can enhance functioning by allowing queries to execute faster.
6. Use Caching Mechanisms
Caching Mechanism, well-received to reduce your directory cost, stores the data that is accessed more often in memory for faster retrieval.
This approach speeds up response times for queries when the same information is requested multiple times.
7. Optimize WHERE Clause Usage
The main purpose of the WHERE clause in SQL (Structured Query Language) is to filter the required data.
It is advisable to avoid functions in this, such as UPPER(column_name), which helps maintain index efficiency.
Instead you can use the columns in the WHERE clause that enables narrowing down the search by limiting the number of records scanned.
8. Reduce Subqueries and Use Joins Where Applicable
Having too many subqueries can really bog down performance, especially with large datasets.
However, you can opt for JOIN instead which will speed things up by merging data from various tables in a more efficient way.
Plus, if you optimize those subqueries with indexing, you’ll see even better results, or you can use Common Table Expressions (CTEs) to improve query readability.
9. Limit the Use of ORDER BY and GROUP BY
Sorting and grouping large datasets can surely drain resources; in that instance, to help your queries run smoother, try to limit the use of ORDER BY and GROUP BY.
If you do need them, consider indexing the columns you’re sorting to boost performance.
In addition, if you limit the number of records processed using LIMIT or TOP, it will lead to improved query efficiency.
10. Maintain Database Statistics and Regularly Update Indexes
Regularly updating your database statistics and indexes is key to helping the system get a better grasp of your data.
As consistent maintenance keeps your directory running at its best, this way, it can execute queries more efficiently.
SQL Server, MySQL, and PostgreSQL are some of the database systems that provide hands-free operations features such as ANALYZE TABLE, UPDATE STATISTICS.
In addition, index rebuilding will ensure that query optimizers have the latest information about the distribution of the reports.
Do You Know? In 1979, Relational Software, Inc. (now Oracle) introduced the first commercially available implementation of SQL. Today, SQL is accepted as the standard RDBMS language.
11. Optimize Transactions and Use Batching
Shortening your transactions and using COMMIT can significantly enhance database performance.
This approach minimizes wait times, avoids locking problems, and allows for more efficient processing of multiple queries simultaneously.
12. Leverage Stored Procedures and Prepared Statements
Using stored procedures and prepared statements can really speed up your queries by allowing you to reuse prewritten code.
They not only make your retrieval commands more efficient but also enhance security, reducing the risk of issues like SQL injection.
Conclusion
In conclusion, as stated before, taking the time to effectively optimize SQL queries can be tremendously beneficial for your efficiency and for your overall productivity.
Slow paced retrieval commands can become your worst enemy, however, putting the strategies we covered into action will surely create a positive impact.
As shared throughout this blog, complex large datasets will no longer come across as challenging, but more so as an opportunity to save on time and minimize problems.
Utilizing these methods surely paves the way towards better SQL optimization and enhanced productivity.
FAQ
What is Query Optimization?
Query optimization is the process of locating the most efficient way to run a SQL statement to improve the speed of data retrieval and to minimize the usage of resources.
Why should SELECT* be avoided in the queries?
When you use a SELECT* in the query, it can lead to various issues, such as slow performance, and can retrieve all columns from a table.
What type of JOIN to use in SQL?
You will be required to use join types such as INNER JOIN, LEFT JOIN, and RIGHT JOIN.
What is Catchy Mechanism?
Catchy Mechanism is a buffering technique that enables you to store and access data from memory for faster retrieval.
Why limit the use of ORDER BY and GROUP BY?
You must try to limit the use of ORDER BY and GROUP BY, this will improve the performance of the query, reduce unnecessary sorting and grouping operations.