In an increasingly data-driven world, privacy concerns have taken center stage. As more and more personal information is collected, processed, and analyzed, safeguarding the privacy of individuals has become a pertinent challenge.
Enter synthetic data generation, a revolutionary approach that promises to transform the data security landscape.
In this article, we will explore the concept of synthetic data generation and its potential to revolutionize its privacy.
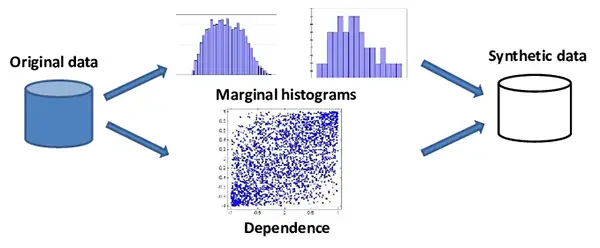
It is a cutting-edge technique in machine learning and artificial intelligence that involves creating artificial datasets that mimic the statistical properties of real information. It is basically generated when the original data is unavailable or must be kept hidden due to personally identifiable information (PII) or compliance problems.
Unlike traditional anonymization methods that may leave residual privacy risks, it generates an entirely new database that is statistically similar to the original one but does not contain any real information about individuals.
The process typically involves using advanced machine learning algorithms, such as generative adversarial networks (GANs) or differential security techniques, to create artificial data that retains the vital characteristics of the original information.
These generated information pools can be used for various purposes, such as testing machine learning models, sharing figures for research, and improving analytics, all while preserving individual secrecy.
It is created in a digital environment. In summary, synthetic data generation is a powerful tool that addresses the pressing need to balance its security and utility.
Do You Know?
In 2022, the synthetic data generation market was valued at 163.8 million, and from 2023-2030, it is estimated to grow at a CAGR of 35%.
This is a significant leap forward in data protection, as conventional anonymization techniques may still leave individuals vulnerable to re-identification attacks.
This promotes collaboration and the advancement of research while mitigating privacy concerns.
Machine learning scientists can work with artificial datasets that mimic real-world scenarios while avoiding the ethical and legal challenges associated with using actual information.
Organizations can continue their data-driven operations while adhering to strict privacy laws.
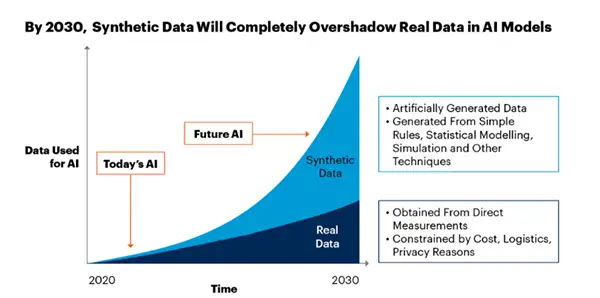
While it holds great promise for security, it is not without challenges and considerations:
If not generated accurately, it may lead to erroneous conclusions and ineffective model training.
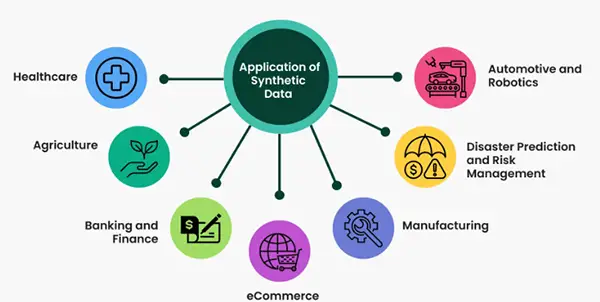
There are various fields where it can be applied including banking and financial services, robotics, automotive and manufacturing, intelligence, and security firms.
For example, in the field of healthcare, it is used to construct models and several datasets in testing. In medical imaging, it is utilized to train AI models while keeping patient privacy in mind. Moreover, they are also using synthetic data to foresee and predict disease trends.
Interesting Fact
As per a recent study, by 2030, synthetic data is projected to surpass actual data due to reasons such as security, data privacy, and the necessity to augment the current database.
In an era where data privacy is of utmost concern, synthetic data generation emerges as a powerful tool to protect individuals while still allowing organizations to leverage the benefits of number crunching.
Creating artificial datasets that preserve the statistical properties of real information helps us to revolutionize its confidentiality and pave the way for a more secure and responsible data-driven future.
As technology continues to advance, it will play a pivotal role in striking the delicate balance between its utility and privacy protection.
To generate Al-generated synthetic data, you must first send a data sample of your
original data to the data generator in order for it to understand statistical features such as
correlations, distributions, and hidden patterns. There are various free data generators available online that you can search for simply on the internet.
It enhances privacy protection, improves the robustness of the machine learning
systems, promotes collaboration, and reduces the need to collect extensive information.
Generally, there are three categories of it, fully synthetic data, partially synthetic data,
and hybrid synthetic data.
lt has the same meaning as the actual sample on which the algorithm was trained.
Since it has the same insights and connections as the original, the original synthetic
dataset is an excellent substitute.
It is generated by computer algorithms or simulations.