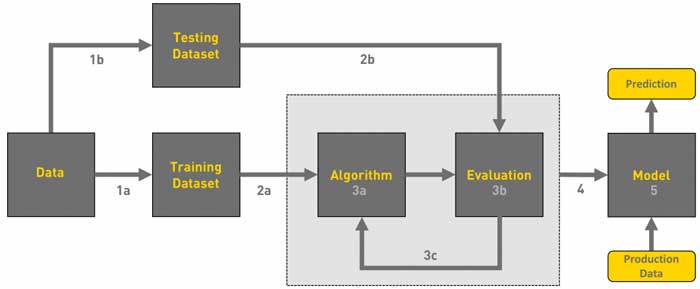
A machine learning chain workflow is the process of developing an application that contains a machine learning model to solve a given business problem. Machine learning is used to solve many problems in the e-commerce segment. For example, data collection and systematization, information processing, designing information solutions. Ultimately, one of the main goals of machine learning is to determine future consumer preferences or predict the behavior of a buyer in new conditions of choice.
From a technical point of view, the development of a machine learning cycle includes typical aspects of the development of a software module.
Before starting any production process or developing a software product, you need to set a task and a goal. This is an invariable attribute of the success of any project, regardless of the intended purpose. How the task is formulated is not so unimportant. No wonder many marketers say that “a correctly formulated goal is already half achieved.”
The construction of a machine learning algorithm is based on the mechanism of static data analysis. The latter is a very important argument, especially for complex computational problems. Operating with qualitative data ultimately determines the success of the result. Machine learning companies will teach you how to work with data correctly.
The typical mechanics of a machine learning module is expressed in a simple formula: processing a set of data X – to predict actions Y. Detailed data or lack of information can fundamentally affect the quality of the result.
For example, the image identification algorithm model used by the social network Facebook uses a deep learning model that does not require operator intervention. This technology has demonstrated that it is possible to determine the content of a photo with high accuracy and sort the content with minimal or no intervention from the employee of the moderator. If there is enough data, and the system can independently fragment the image and identify thematic content, the function of accepting or rejecting content becomes only a little conventional. At the same time, with the complexity of the task. For example, processing a photo with not one character, but with several system fragments, may require additional practical examples or software modules.
As practice shows, learning algorithms show accurate results when working with a large set of informative data. The more detailed and informative the data is used, the better the result will be.
As a result, data sources and completeness of information play a key role in the machine learning workflow. Today, due to legal restrictions on access to personal data, some information may be closed. This will require some manual adjustment or additional costs.
The choice of a machine learning algorithm directly affects the speed and quality of the result. When it comes to processing unlabeled data to predict the situation, a controlled algorithm is used. When an engineer works with an unlabeled set of data grouped into different categories, an unsupervised algorithm is applied, that is, without self-assessment of informative data.
Depending on the amount of training and the nature of the algorithm, the data processing process can take from one minute to several days. The latter situation is relevant in deep learning, when the algorithm includes a learning process, such as learning the rules of a certain game or production process. Algorithms based on short data sets, such as image identification or music track identification, do not require large computational resources.
If you want to learn more follow this link.




